오늘은 RAG의 두 가지 변형, RAG-Sequence와 RAG-Token 모델에 대해 설명하겠습니다.
먼저 조건부 확률을 모두 이해하고 가보겠습니다.

친구가 평소에 우산을 가져올 확률이 40%라고 해요. 그런데 오늘은 비가 오는 날이에요. 비 오는 날에는 친구가 우산을 가져올 확률이 더 높겠죠? 이 렇게 "비가 오는 날"이라는 (조건) 이 주어진 상태에서 친구가 우산을 가져올 (확률)을 조건부 확률이라고 합니다. 수식으로 쓰면 p(친구가 우산을 가져온다 | 비가 오는 날) 라고 쓸수 있겠죠.
A = 비가 오는 날, B = 우산을 가져오는 것
P(B|A) = 비가 오는 날이라는 조건 때문에 "우산을 가져올 확률"이 더 달라지는 거예요.
이처럼 조건부 확률은 어떤 조건이 주어진 상황에서 다른 사건이 일어날 확률을 말해요.
자, 이제 본격적으로 RAG의 수식을 살펴보겠습니다.

1. RAG-Sequence 모델
수식
$$p_{\text{RAG-Sequence}}(y | x) \approx \sum_{z \in \text{Top-k}(p(z|x))} p_{\eta}(z | x) p_{\theta}(y | x, z)$$
주요 용어와 의미
- \( x \) : 질문 또는 입력 텍스트 (Query)
- \( y \) : 생성된 답변 또는 출력 텍스트 (Answer)
- \( z \) : 검색된 문서 (Document)
- \( \text{Top-k}(p(z|x)) \) : \( x \) 와 관련된 상위 \( k \) 개의 문서들 (검색 엔진이 선택한 \( k \) 개의 문서)
- \( p_{\eta}(z | x) \) : 질의 \( x \) 에 대해 문서 \( z \) 가 선택될 확률 (검색 확률)
- \( p_{\theta}(y | x, z) \) : 문서 \( z \) 와 질문 \( x \) 를 기반으로 답변 \( y \) 가 생성될 확률 (생성 모델 확률)
설명
- 문서 검색 단계
- 검색 엔진이 \( x \) 에 대해 관련성이 높은 \( k \) 개의 문서를 선택합니다 \( \text{Top-k}(p(z|x)) \)
- 문서 선택 확률 계산 (\( p_{\eta}(z | x) \))
- 각 문서가 질문 \( x \) 와 얼마나 관련이 있는지를 확률적으로 계산합니다.
- 답변 생성 확률 계산 (\( p_{\theta}(y|x, z) \))
- 선택된 문서 \( z \) 와 질문 \( x \) 를 기반으로 답변 \( y \) 를 생성합니다.
- 결합 및 합산:
- 상위 \( k \) 개의 문서 각각에 대해 계산된 확률 값을 합산하여 최종 확률을 계산합니다.
비유
질문을 받았을 때
- 도서관에서 가장 관련 있는 \( k \) 권의 책을 선택하고,
- 각 책의 중요도를 계산한 다음,
- 그 책을 참고하여 답변을 작성하고,
- 모든 책에서 얻은 정보를 종합하여 최종 답변을 만드는 방식입니다.
2. RAG-Token 모델
수식
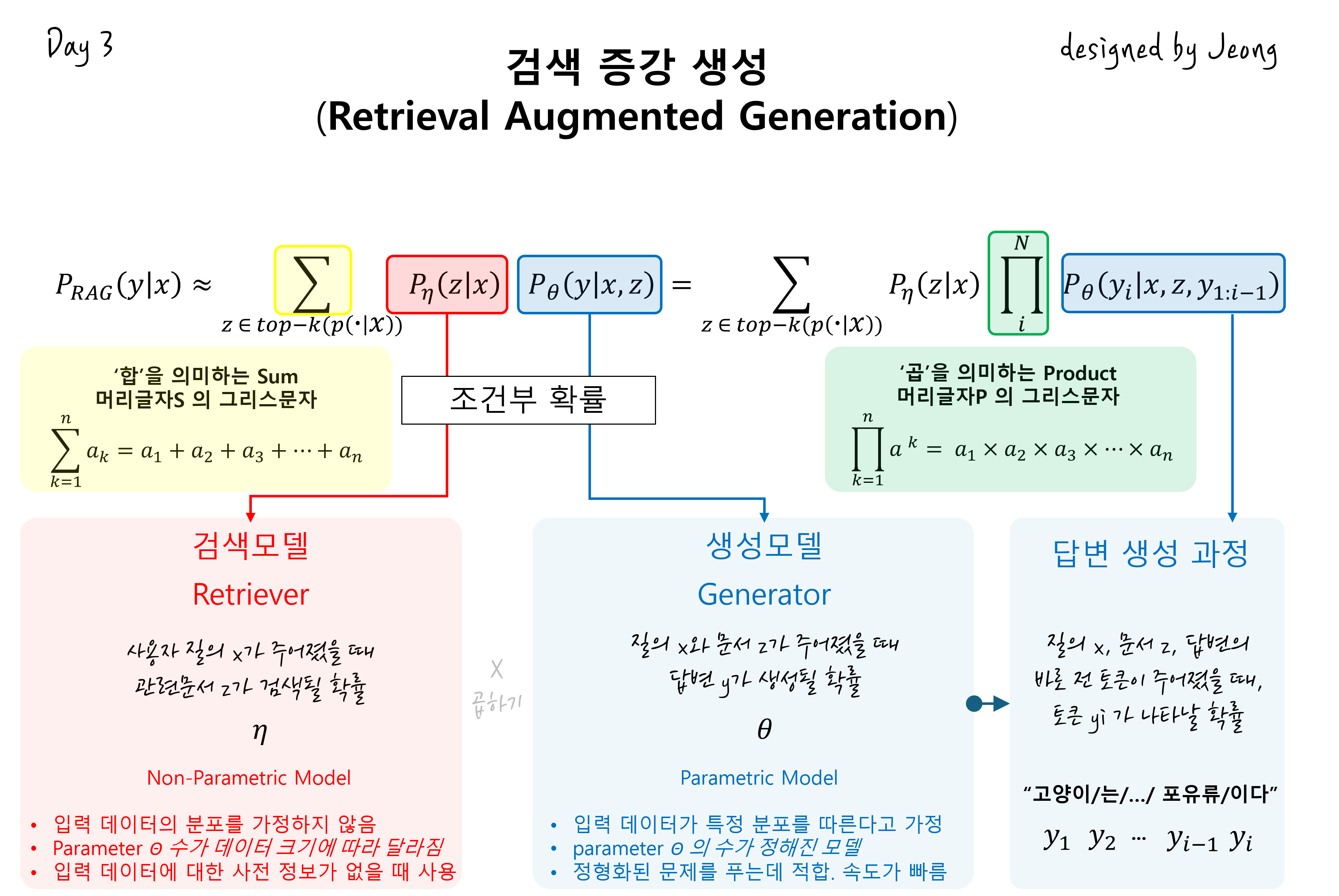
$$p_{\text{RAG-Token}}(y | x) \approx \prod_{i=1}^{N} \sum_{z \in \text{Top-k}(p(z|x))} p_{\eta}(z | x) p_{\theta}(y_i | x, z, y_{<i})$$
주요 용어와 의미
- \( y_i \) : 생성된 답변의 i-번째 토큰 (Answer Token)
- \( y_{<i } \) : i-번째 토큰 이전까지 생성된 모든 토큰 (Context)
- N: 답변 y의 총 토큰 개수 (Answer Length)
- 나머지 기호 ( \( x \) \( y \) \( z \) \( \text{Top-k}(p(z|x)) \) \( p_{\eta}(z | x) \) \( p_{\theta} \) )
: RAG-Sequence 모델에서 사용된 것과 동일
설명
- 문서 검색 단계
- x에 대해 상위 \( k \) 개의 문서를 검색합니다 \( \text{Top-k}(p(z|x)) \)
- 각 토큰 생성 단계
- i-번째 토큰을 생성할 때, 선택된 문서 z와 질문 x, 그리고 이전에 생성된 토큰 \( y_{<i } \) 를 바탕으로 확률을 계산합니다. \( p_{\theta}(y_i | x, z, y_{<i}) \)
- 문서 확률 가중치 계산
- 각 문서의 중요도를 확률 \( p_{\eta}(z | x) \) 로 가중치 부여합니다.
- 곱 계산
- 각 토큰의 생성 확률을 곱하여 최종적으로 답변 전체의 확률을 계산합니다.
예제 문장
사용자가 질문: "고양이는 어떤 동물인가요?"
RAG 모델이 문서 검색 후 답변 생성: "고양이는 포유류입니다."
아래는 RAG-Token 모델이 답변을 생성하는 과정을 나타냅니다.
1. 먼저 사용자가 질문(x)을 합니다.
"고양이는 어떤 동물인가요?"
2. RAG가 검색된 문서 또는 외부 지식 z 를 찾습니다.
RAG는 먼저 지식 데이터베이스에서 관련 문서들을 검색합니다.
예를 들어, 다음과 같은 문서를 찾을 수 있습니다
3. $\text{Top-k}(p(z|x))$ (가장 관련성이 높은 문서 선택)
모델은 검색된 문서들 중에서 가장 관련성이 높은 k개를 선택합니다.
여기서 "고양이는 포유류이며 육식 동물이다." 문장이 가장 관련성이 높다고 판단될 수 있음.
4. $p_{\eta}(z | x)$ (검색 모델이 특정 문서를 선택할 확률)
검색된 문서가 사용자의 질문과 얼마나 잘 맞는지 확률적으로 평가합니다.
5. $p_{\theta}(y_i | x, z, y_{<i})$ (답변 토큰별 생성 확률)
이제 답변을 생성하는 과정입니다.
첫 번째 토큰: "고양이" → 높은 확률로 선택됨
두 번째 토큰: "는" → 문법적으로 자연스러움
세 번째 토큰: "포유류" → 검색된 문서와 관련이 깊음
네 번째 토큰: "입니다." → 문장이 완성됨
6. 최종 답변 y 생성
위의 과정을 반복하여 "고양이는 포유류입니다." 라는 답변을 완성합니다. 😊
RAG-Sequence와 RAG-Token의 차이점
- RAG-Sequence
- 하나의 문서를 기준으로 전체 답변 y를 생성합니다.
- 단순한 구조로, 한 번에 전체 답변을 생성하는 방식입니다.
- RAG-Token
- 각 토큰마다 다른 문서를 기준으로 생성할 수 있습니다.
- 더 세밀한 제어가 가능하지만 계산량이 더 많습니다.
요약
- RAG-Sequence : 한 문서를 중심으로 답변 전체를 생성.
- RAG-Token : 답변의 각 단어를 생성할 때마다 문서를 새로 선택.
- 두 모델 모두 질문과 검색된 문서를 바탕으로 확률을 계산해 답을 만들어냅니다.
- RAG-Token 모델이 더 유연하지만 계산이 더 복잡합니다.