# 소프트맥스는 왜 자연상수의 지수함수 $e^x$ 를 사용하는가?

Softmax 함수는 다중 클래스 분류에서 확률값을 계산하는 데 사용되는 활성화 함수입니다. 수식은 다음과 같습니다.
$$\sigma(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{n} e^{z_j}}$$
#1. Softmax 함수의 요소
1. \( z_i : \text{입력 벡터의 } i \text{번째 요소} \) 입력값, 로짓
Softmax 함수에 입력되는 원소입니다.
분류 문제에서 각 클래스에 대한 로짓(logit, 점수)으로 사용됩니다.
예를 들어, 뉴런의 출력값이나 신경망의 마지막 계층에서 계산된 값이 됩니다.
2. \( e^{z_i} : \text{자연상수} e \text{를 밑으로 하는} \) 지수 함수
자연상수 (약 2.718)를 밑으로 하여 를 지수로 갖는 함수입니다.
지수 함수를 적용하면 값이 항상 양수가 됩니다.
더 큰 값에 대해 더 큰 확률을 할당하도록 하는 역할을 합니다.
3. \( \sum_{j=1}^{n} e^{z_j} : \text{모든 입력 벡터 요소의 지수 값 합계} \) 분모, 정규화 역할
입력값들의 지수 변환 결과를 모두 합한 값입니다.
모든 클래스에 대한 지수 함수의 합을 분모로 사용하여 확률값의 합이 1이 되도록 보장합니다.
즉, Softmax의 출력값이 확률 분포를 따르도록 만드는 핵심적인 요소입니다.
4. \( \sigma(z_i) : \text{소프트맥스 함수의 출력 (확률 값)} \) Softmax 확률값
각 클래스에 대한 확률 값을 구하는 공식입니다.
입력값들을 정규화하여 전체 합이 1이 되도록 만들며, 가장 큰 입력값에 대해 가장 높은 확률을 부여합니다.
#2. Softmax 함수의 특징
1. 확률 분포 생성 : 모든 출력값이 0~1 사이에 있고, 총합이 1이 됩니다.
2. 입력값의 상대적인 차이 반영 : 값이 클수록 높은 확률을 부여하지만, 모든 값의 관계를 유지합니다.
3. 큰 값이 더 두드러지게 강조됨 : 지수 함수가 사용되므로, 큰 값과 작은 값의 차이가 강조됩니다.
예를 들어,
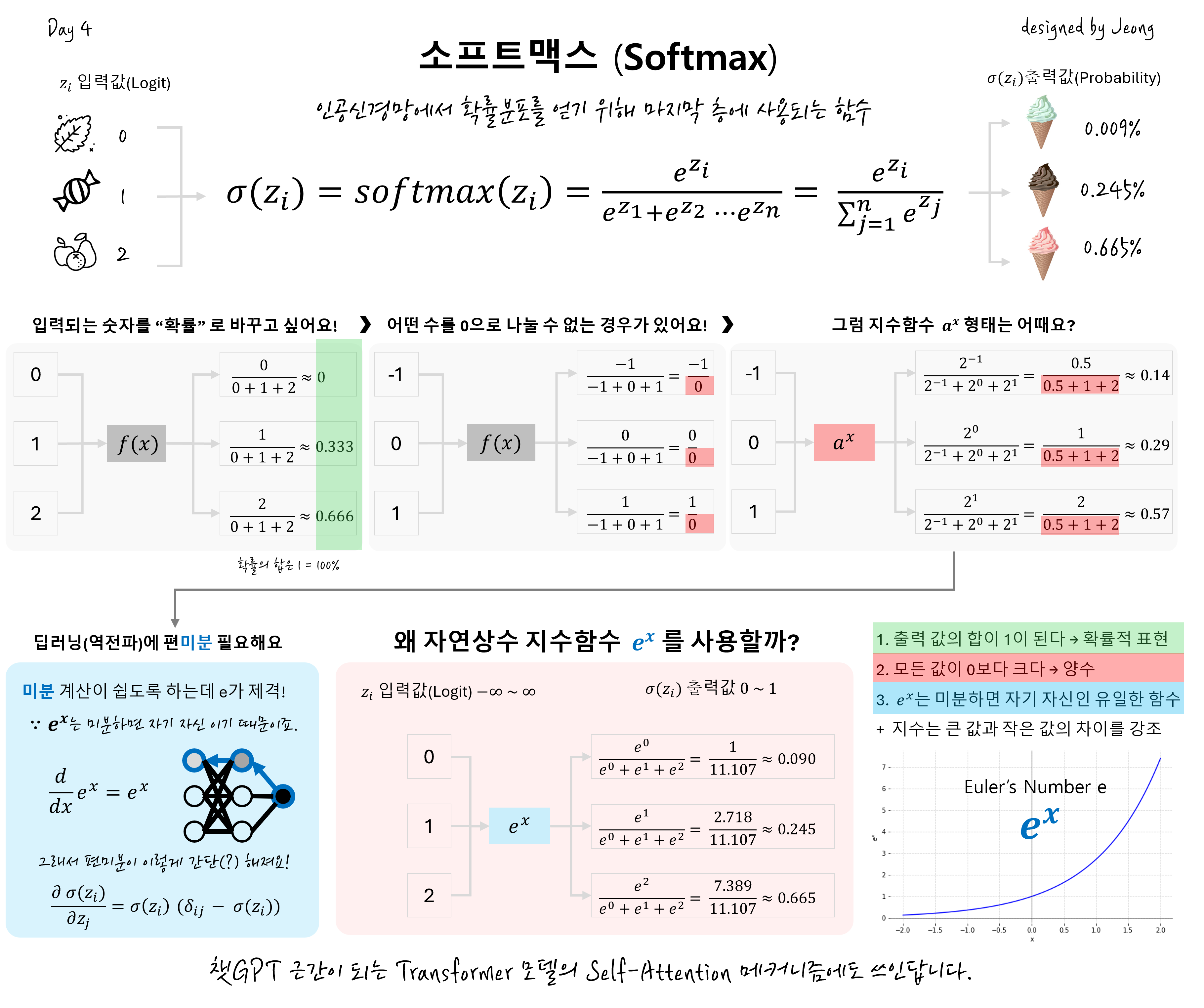
기왕에 "소프트" 라는 이름이 아이스크림을 연상하니까, 아이스크림 예를 들어보겠습니다.
아이스크림 가게에서 특정손님의 맛(flavour) 선호도가 신선한 맛 0, 단 맛 1, 과일 맛 2 로 입력되었을때
최종적으로 손님에게 추천할 맛에 대한 확률을 구하는 문제라고 가정해보겠습니다.
최종적으로 하나의 맛을 선택할 수도 있지만, 손님의 선호 입력값이 많거나, 구매 상품에 따라서 2번째, 3번째 맛도 추천할 필요가 있겠죠. 이런 경우에 입력되는 값은 일반 숫자입니다. 우리는 이 값을 로짓(logit) 이라고 부르기로 합니다.
그리고 출력값을 확률로 계산하여 얻고싶습니다.

그럼 단계적으로 왜 소프트맥스 함수가 저렇게 생겼는지 알아보겠습니다.
일반적인 숫자인 입력값에 대해 출력값을 확률로 바꾸기 위해서는 특정 함수가 필요할 것입니다.
1) 우선 입력되는 숫자를 확률로 바꾸고 싶습니다. 그럴때 우리는 전체 원소를 다 더해서 분모에, 그리고 계산하고자 하는 원소를 분자에 넣어서 비율(%)을 계산합니다. 그러면 출력값의 총 합은 1, 즉 100%가 됩니다.

그런데 문제가 있습니다. 우리가 개발하는 인공지능 모델에서 중간층에서 계산되는 입력되는 값이 항상 0보다 크지는 않다는 점입니다. 예를 들어 입력값이 -1,0,1 인 경우 그림에서 보는 것처럼 분모가 0이 되어, 계산 자체가 불가능합니다.
그래서 생각할 수 있는 방식이 바로 지수함수의 형태 입니다.
지수함수를 사용하면 모든 값이 0보다 큰 양수로 변환할 수가 있죠. 또한 지수는 큰 값은 더욱 크게, 작은 값은 더욱 작게 차이를 강조해주는 역할을 합니다.
여기서 중요한 것이 바로 미분의 개념입니다.
딥러닝에서는 역전파 알고리즘을 사용하여 손실함수의 값을 최적화하는데요. 역전파를 위해 거꾸로 가는 과정에서 특정 원소에 대해 편미분을 수행해주어야 합니다. 그런데 일반 지수함수는 그 계산과정이 복잡해지고, 수의 자릿수가 많아지면서 컴퓨터 계산이 불필요하게 많거나 적어지는 오버플로우/언더플로우 문제가 발생할 가능성이 높습니다.
이 때, 미분을 간단히 수행할 수 있는 지수함수가 바로 $e^x$ 입니다.

Softmax에서 자연상수 를 사용하는 이유는 미분의 편리성 때문인데요.
자연상수의 지수함수는 $e^x$ 는 자기 자신을 미분한 유일한 함수 입니다.
다른 밑(예: 2나 10)을 사용하면 추가적인 로그 스케일링이 필요하여 계산이 더 복잡해지는데,
자연상수의 지수함수는 $e^x$ 는 모든 값이 양수로 만들며, 전체 합이 1이 됨은 물론이고, 항상 양수이므로, 확률로 변환할 때 안정적입니다.
다시 정리하여 Softmax에서 자연상수를 사용하는 이유는 다음과 같습니다.
1. 출력값의 합이 1이 되어, 확률적 표현이 가능하다.
(확률적이라고 명시한 이유는 이것이 정확히 확률을 의미하지는 않고 상대적 크기를 확률로 나타내는 개념)
2. 모든 값이 양수가 되어 계산이 용이하다.
3. 미분 과정이 단순해져, 수치적으로 안정적이어서 부동소수점 연산에서 오버플로우/언더플로우 문제를 줄인다.
그 외에 자연로그와 일관성이 유지되어 크로스 엔트로피 손실과 잘 맞는다는 장점도 있습니다.
#3. Softmax 를 활용한 연구논문
Softmax를 사용한 가장 유명한 논문 중 하나는 구글이 2017년 발표한 "Attention Is All You Need" (2017, Vaswani et al.)입니다. 이 논문은 Transformer 모델을 제안했으며, 자연어 처리(NLP)에서 혁신적인 마일스톤입니다.
논문 제목 : Attention Is All You Need
저자 : Ashish Vaswani 외
출판연도 : 2017
링크 : https://arxiv.org/abs/1706.03762
이 논문 Transformer에서 Softmax는 Attention 가중치를 계산하는 데 사용됩니다.
주어진 Query \( Q \), Key \( K \), Value \( V \)에 대해 Attention은 다음과 같이 정의됩니다:
\[
\text{Attention}(Q, K, V) = \text{softmax} \left( \frac{QK^T}{\sqrt{d_k}} \right) V
\]
여기서,
- \( Q \) (Query) : 현재 단어의 의미를 찾기 위한 벡터
- \( K \) (Key) : 다른 단어들과의 유사도를 측정하기 위한 벡터
- \( V \) (Value) : 문장에서 정보를 담고 있는 벡터
- \( d_k \) : Key 벡터의 차원 수 (스케일링을 위해 사용)
Softmax는 각 단어의 중요도를 확률 분포로 변환하는 역할을 합니다. Softmax는 다음과 같이 동작합니다:
\[
\alpha_{ij} = \frac{\exp \left( \frac{q_i \cdot k_j}{\sqrt{d_k}} \right)}{\sum_{j} \exp \left( \frac{q_i \cdot k_j}{\sqrt{d_k}} \right)}
\]
여기서,
- \( \alpha_{ij} \)는 Query \( q_i \)가 Key \( k_j \)에 대해 얼마나 집중해야 하는지를 결정하는 가중치입니다.
앞서 살펴본 Softmax의 역할과 마찬가지로, 다음의 기능을 합니다.
1. Attention 가중치를 확률 분포로 변환
2. Softmax는 모든 값이 0~1 사이가 되도록 정규화하여, 모델이 특정 단어에 집중하도록 만들어 Self-Attention에서 중요한 단어 강조하죠.
3. Transformer는 문장의 모든 단어를 서로 비교하며, Softmax를 통해 유사도가 높은 단어에 높은 가중치를 부여합니다.
이것이 가중치를 확률적 분포로 해석할 수 있게 히야 학습이 더 안정적으로 진행됩니다.
'인공지능(AI) 이론과 코드 > 4. 딥러닝' 카테고리의 다른 글
| 경사 하강법 Gradient Descent 에 대한 수학적 이해와 활용 (1) | 2025.01.12 |
|---|---|
| [Class 상속의 개념] super().__init__() 의 원리와 이해 (1) | 2022.02.24 |
| 딥러닝 및 컴퓨터 비전 학회, 논문, 저널 (0) | 2021.10.08 |


