왜도(skewness) : 비대칭도
[ 한 줄 정의 ]
데이터가 관측될 확률 분포의 비대칭성을 나타내는 지표
[ 수식 ]
∑(Xi - x)3
skewness = -------------------- , (여기서 x는 Xi의 평균치)
{∑(Xi-x)2}3/2
[ 설명 ]
○ 왜도는 보통 γ1(감마) 라는 기호를 사용한다.
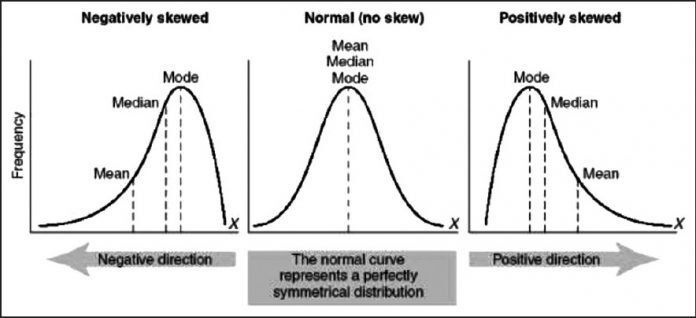
○ 양수(Positive)나 음수(Negative) 또는 0이 될 수 있다.
- 양수 : 확률밀도함수의 오른쪽 부분에 긴 꼬리를 가지며(Right-skewed), 중앙값을 포함한 자료가 왼쪽에 더 많이 분포
- 음수 : 확률밀도함수의 왼쪽 부분에 긴 꼬리를 가지며(Left-skewed), 중앙값을 포함한 자료가 오른쪽에 더 많이 분포
- 0 : 평균과 중앙값이 같으면 왜도는 0이다.
음수 Negative = Left 꼬리 양수 Positive = Right 꼬리
[ 적용 ]
-2 미만은 Negative Skew
+2 초과는 Positive Skew
Skew 데이터를 변환하는 이유 : 꼬리 부분에 있는 데이터를 모델에 제대로 학습시키기 위함
Skewed 되어있는 데이터를 그대로 학습시키면 꼬리 부분이 상대적으로 적고 멀어서 모델에 영향이 거의 없이 학습
만약 꼬리 부분에 유의미한 데이터가 있다면, test 데이터의 꼬리 부분에 대해 모델의 정확도가 떨어진다.
반면, 변환을 하면, 그만큼 데이터의 중간값 또는 평균이 꼬리부 하고 가까워져서 기존보다 모델에 잘 반영된다.
따라서 꼬리 부분에 해당하는 test 데이터가 들어와도 정확도가 높아진다.
Skew 데이터를 변환하는 방법으론 루트(square root), 세제곱 루트(cube root), 로그(log), outlier 제거 등이 있다.
- Positive skewed(right skewed) 변환방법 : 루트 / 세제곱 / log 10
- Negative skewed(left skewed) 변환방법 : 제곱 / 세제곱 루트 / log
첨도(kurosis; 커토시스) : 뾰족한 정도
[ 한 줄 정의 ]
데이터가 관측될 확률 분포가 뾰족한 정도를 나타내는 지표
[ 수식 ]
∑(Xi - x)4
Kurtosis = ------------------ - 3 (여기서 x는 Xi의 평균)
{∑(Xi-x)2}2
[ 설명 ]
○ 첨도는 보통 K(케이) 기호를 사용한다.
○ 정규분포일 경우 K=3을 기준으로 아래와 같은 특성을 가진다.
- 큰값 K>3 : 3보다 큰 양수이면(K>3) 정규분포보다 꼬리가 두껍다.(t-분포)
Peak가 중심보다 높고 뾰족하다.
이상치가 많다.
- 작은값 K<3 : 3보다 작을 경우에는(K<3) 산포는 정규분포보다 꼬리가 얇다.
Peak가 중심보다 낮고 완만하다.
이상치가 적다.
- 정규분포 K=3

'빅데이터(Big Data) 이론과 코드 > 6. 통계지식' 카테고리의 다른 글
| 최대 우도 추정법(Maximum Likelihood Estimation, MLE) (0) | 2025.01.06 |
|---|---|
| 예산과 전문가 없이 데이터로 인포그래픽을 만들기 (1) | 2024.06.25 |
| 마트 홈런볼과 편의점 홈런볼의 독립표본 t검정 (2) | 2023.01.18 |
| 홈런볼 슈링크플레이션과 소비자 물가지수 (2) | 2023.01.09 |
| [홈런볼로 배우는 데이터 경제] t검정 (2) | 2022.12.26 |



